Generic Model for Multi-modal Perception
We are dedicated to advancing the field of Multi-modal Generalist Model through innovative approaches. We aim to investigate unified task representations, network architecture, and training methods for visual and graph-text multi-modal tasks. We also seek to construct a generalist model for multi-modal tasks that encompasses various applications. In addition, we strive to design a novel universal perceptual paradigm based on large-scale models to achieve comprehensive capabilities geared toward open-world scenarios and open-ended tasks.
Representative Work:
Unified Pre-training Algorithm for Large-scale Vision-Language Models
-
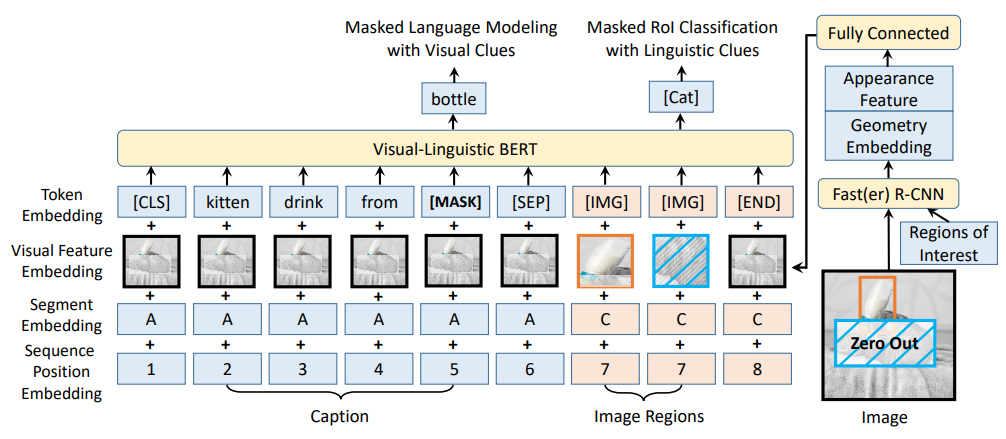
VL-BERT: Pre-training of Generic Visual-Linguistic Representations
[ICLR 2021 7th most influential paper]
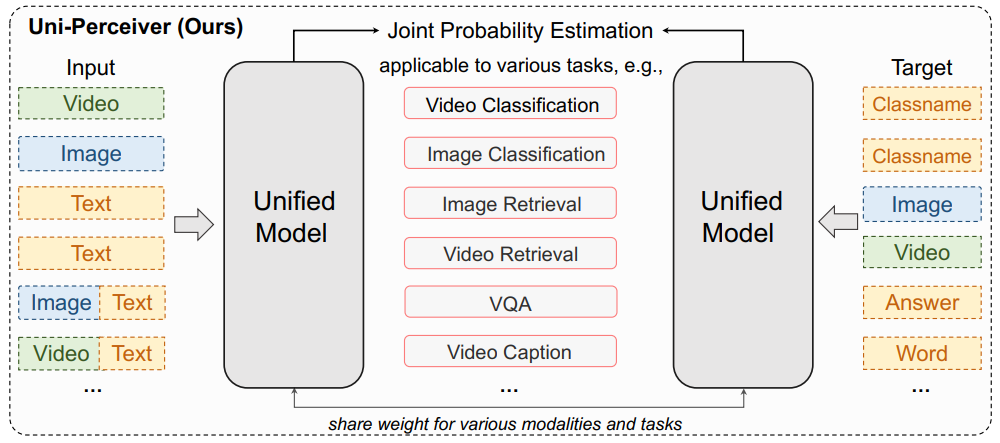
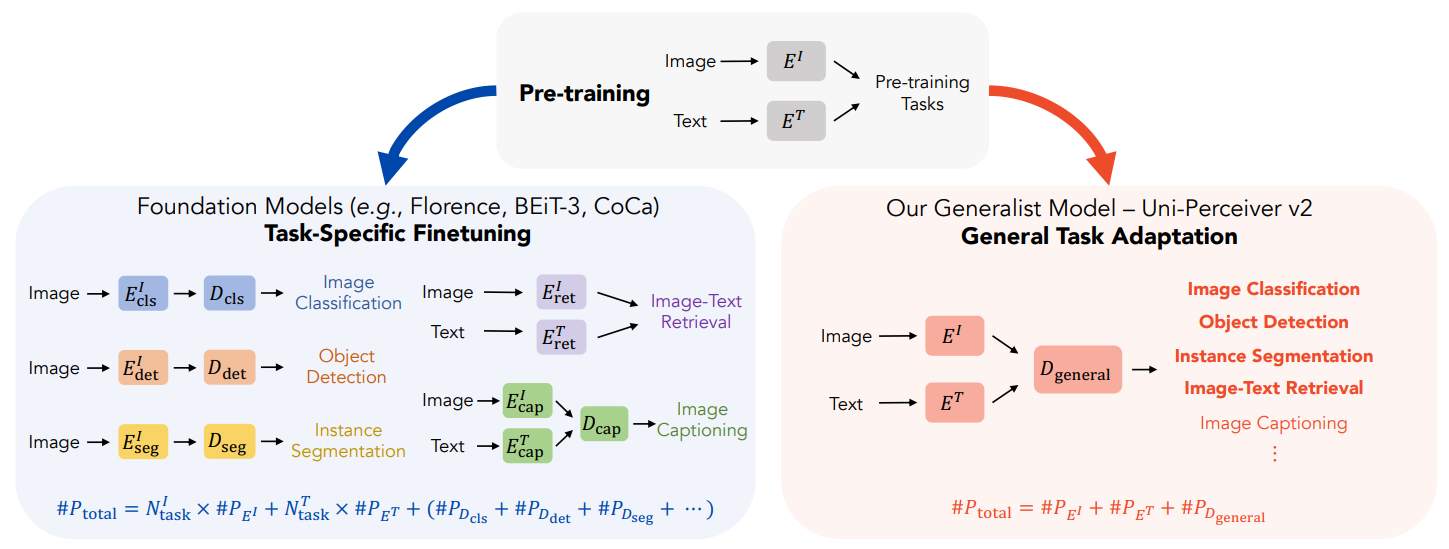
Unified Modeling and Architecture for General Multi-modal Perception Tasks
-
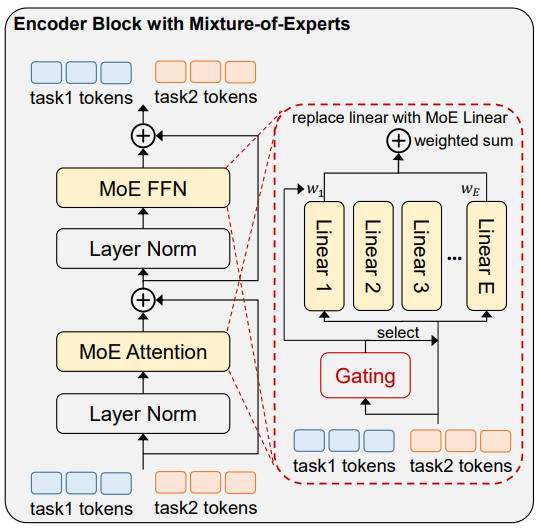
Uni-Perceiver-MoE: Learning Sparse Generalist Models with Conditional MoEs
[NeurIPS 2022 Spotlight paper]
-
Uni-Perceiver v2: A Generalist Model for Large-Scale Vision and Vision-Language Tasks
[CVPR 2023 Highlight paper]
Large Vision-Language Model for Open-Ended Vision-Centric Tasks