Blog
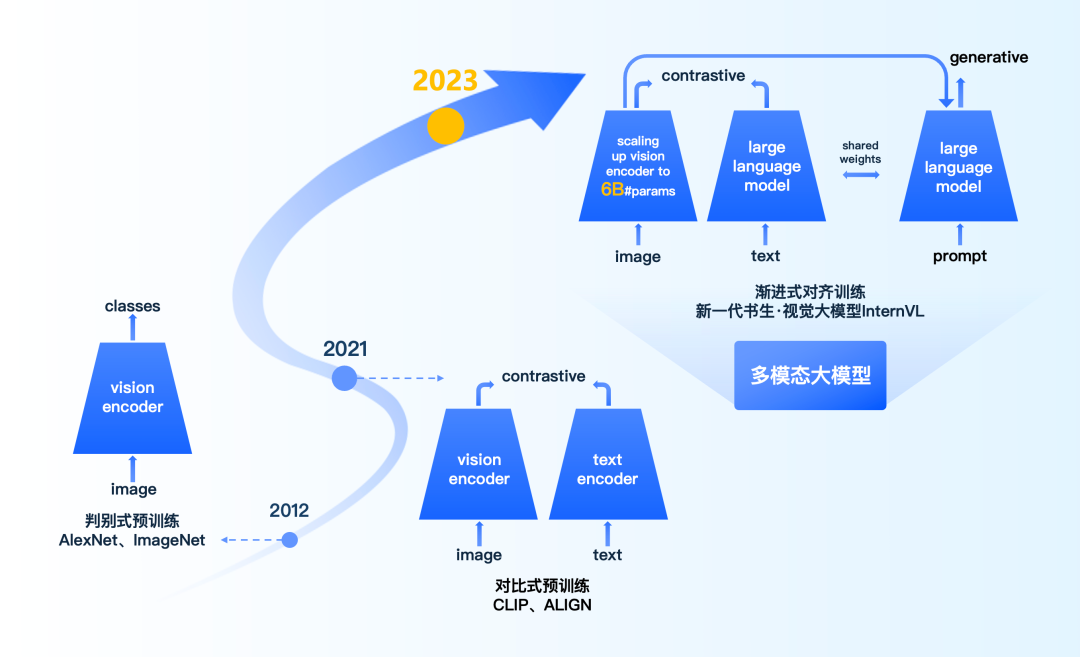
本实验室联合上海AI实验室发布新一代书生·视觉大模型,视觉核心任务开源领先
新一代“书生·视觉基础”模型的视觉编码器参数量达60亿(InternVL-6B),首次提出了对比-生成融合的渐进式对齐技术,实现了在互联网级别数据上视觉大模型与语言大模型的精细对齐。
本实验室联合发布最强开源多模态生成模型MM-Interleaved:首创特征同步器
MM-Interleaved 可以轻松编写引人入胜的旅游日志和童话故事,准确理解机器人操作,就连分析电脑和手机的 GUI 界面、创作独特风格的精美图片都不在话下。甚至,它还能教你做菜,陪你玩游戏,成为随时听候指挥的个人助理!
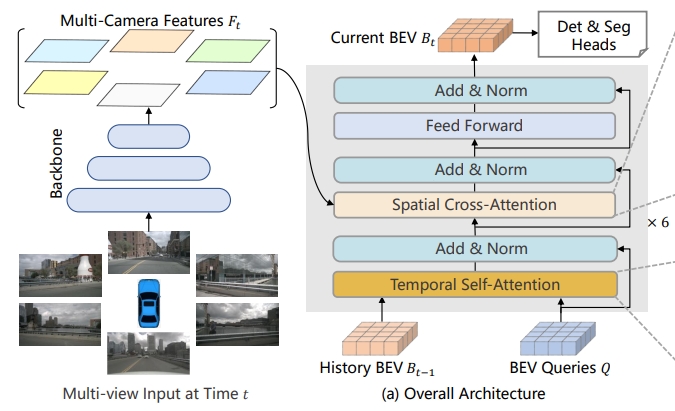
万字长文理解纯视觉感知算法 —— BEVFormer
BEVFormer 是本实验室发表在 ECCV 2022 上的一篇论文,其中提出了一个采用纯视觉(camera)做感知任务的算法模型 BEVFormer,并取得了 SOTA 的效果。
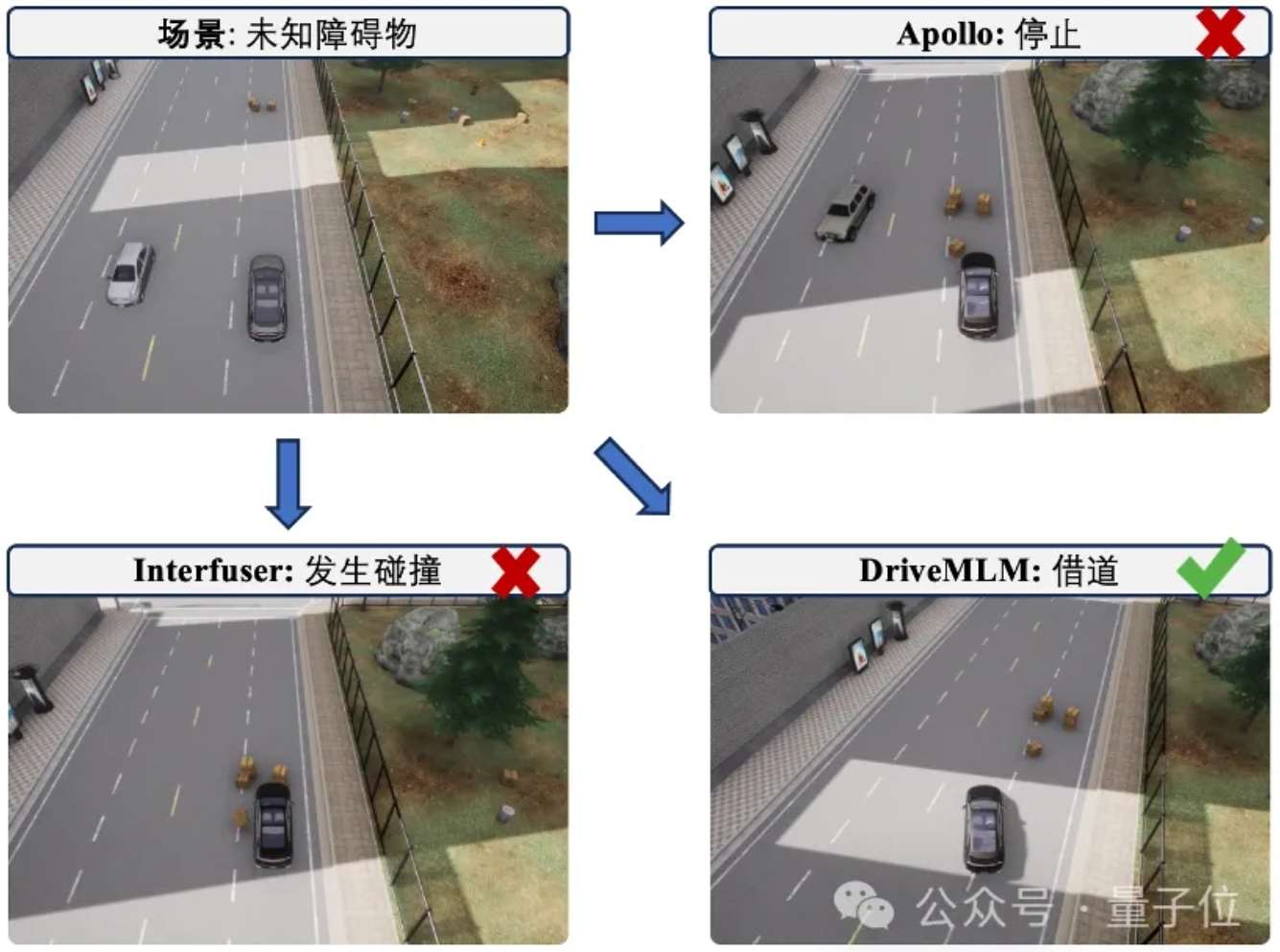
本实验室联合商汤用多模态LLM做自动驾驶决策器,可解释性有了!比纯端到端更擅长处理特殊场景
最新自动驾驶大模型DriveMLM,直接在闭环测试最权威榜单CARLA上取得了SOTA成绩——跑分比基线Apollo还要高4.7,令一众传统模块化和端到端方法全都黯然失色。

本实验室联合商汤发布通才智能体完全解锁《我的世界》,像人类一样生存,探索和创造
AI 也能应对开放世界,像人类一样生存,探索和创造!

CVPR最佳论文奖首次给了自动驾驶:大模型加持,感知决策一体,出自本实验室
国内的自动驾驶,终于走在世界前列!近十年来计算机视觉三大顶级会议中,第一篇来自中国研究团队的最佳论文。
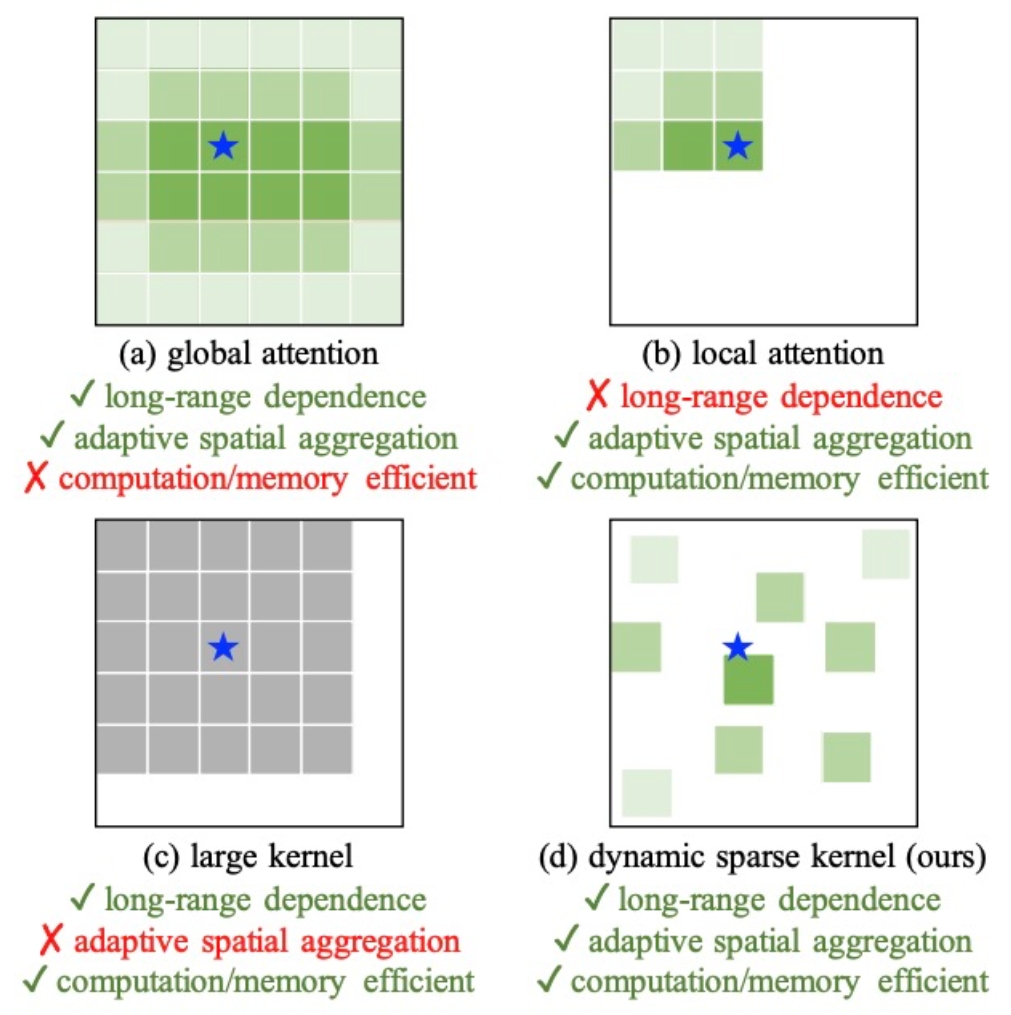
来自本实验室!用CNN做基础模型,可变形卷积InternImage实现检测分割新纪录
InternImage-H 在 COCO 物体检测上达到 65.4 mAP,ADE20K 达到 62.9,刷新检测分割新纪录。
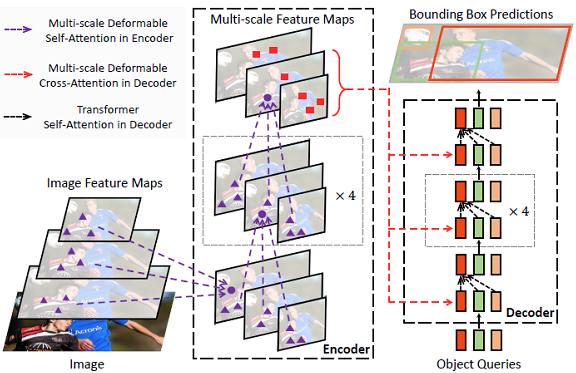
本实验室提出 Deformable DETR:基于稀疏空间采样的注意力机制,让DCN与Transformer一起玩!
DETR提出后,Transformer就被带到目标检测这边玩起来了,而且还能玩出各种花样!
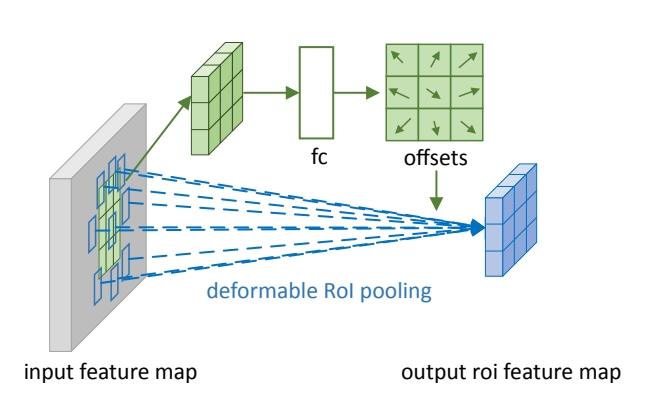
本实验室提出可变形卷积网络:计算机新“视”界
图像识别于两年多前首次超越了人类的识别能力。物体检测、图像分割等也都达到了几年前传统方法难以企及的高度。

本实验室实习生李志琦获2024英伟达奖学金名单!
这是该奖首次发给我国内地高校学生