Publications
We try our best to do research with long-term impact.
Highlighted
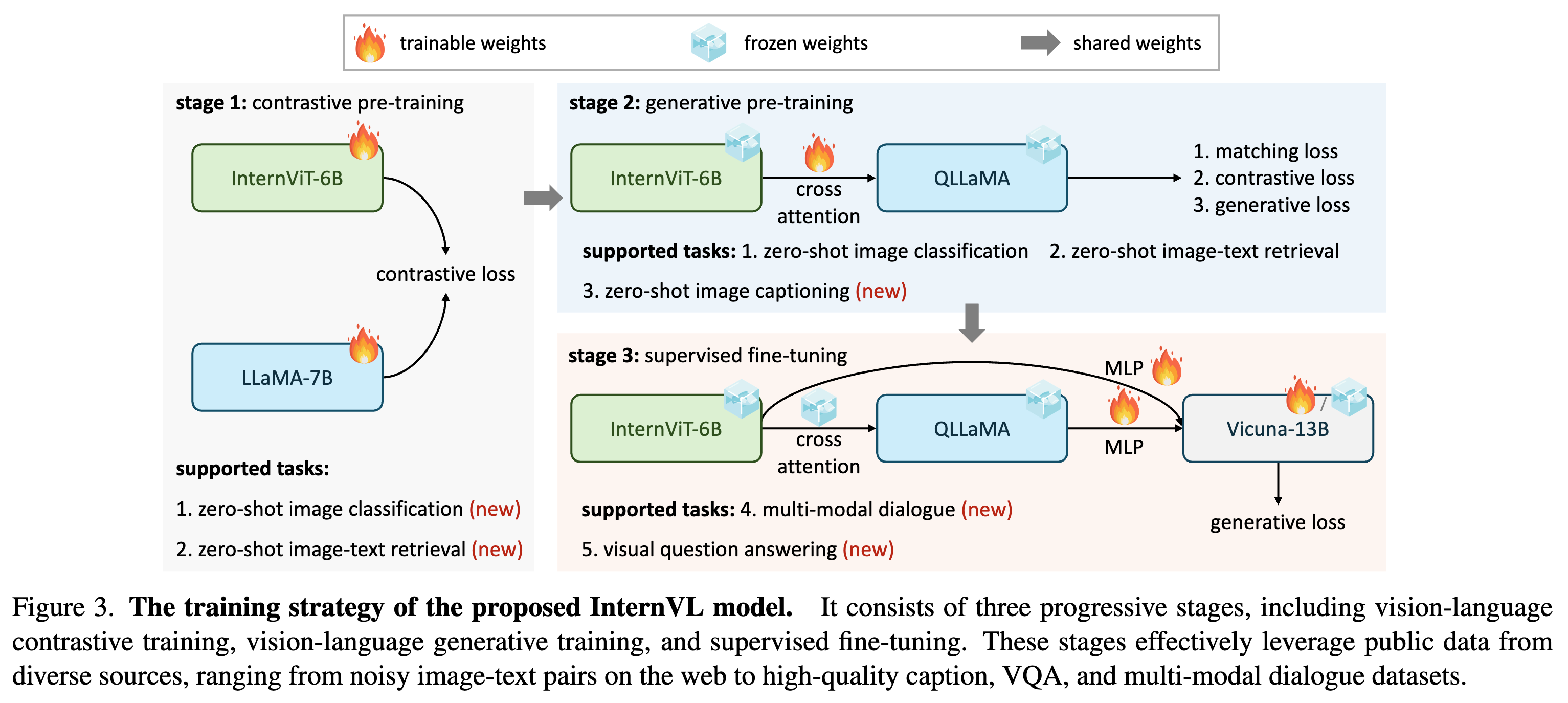
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks

CVPR 2024 (Oral)
·
18 Jan 2024
·
arxiv:2312.14238
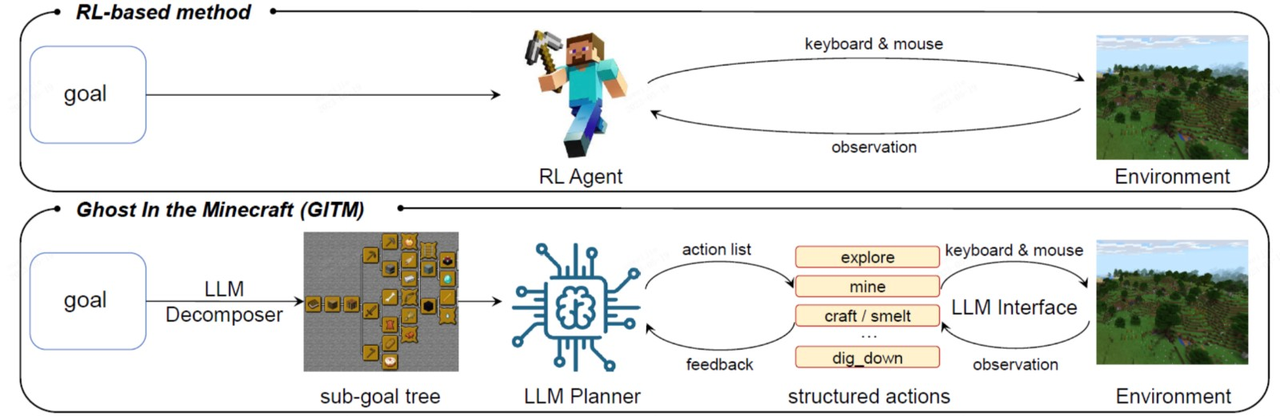
Ghost in the Minecraft: Generally Capable Agents for Open-World Environments via Large Language Models with Text-based Knowledge and Memory

Arxiv Tech Report 2023
·
02 Jun 2023
·
arxiv:2305.17144

VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks

NeurIPS 2023
·
26 May 2023
·
arxiv:2305.11175
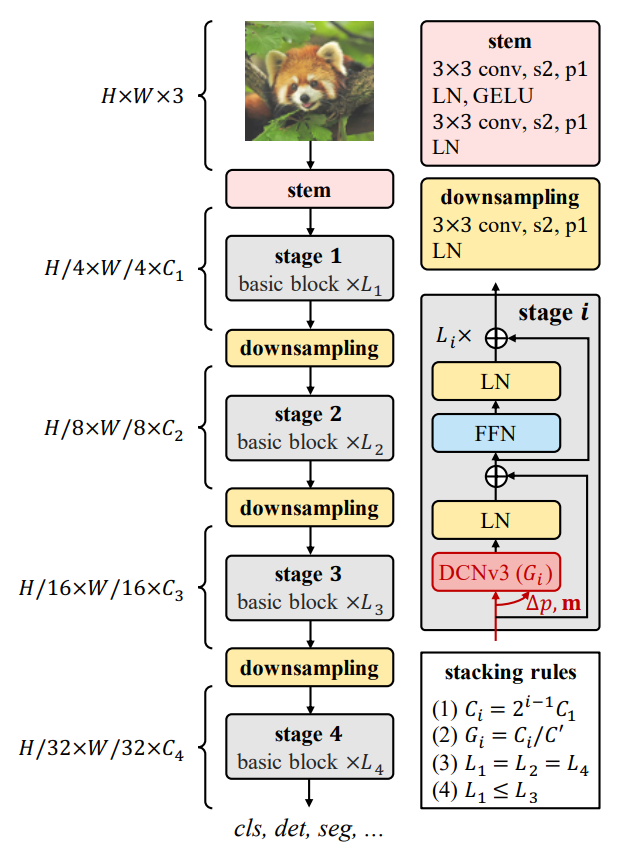
InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions

CVPR 2023 (Highlight)
·
18 Apr 2023
·
arxiv:2211.05778

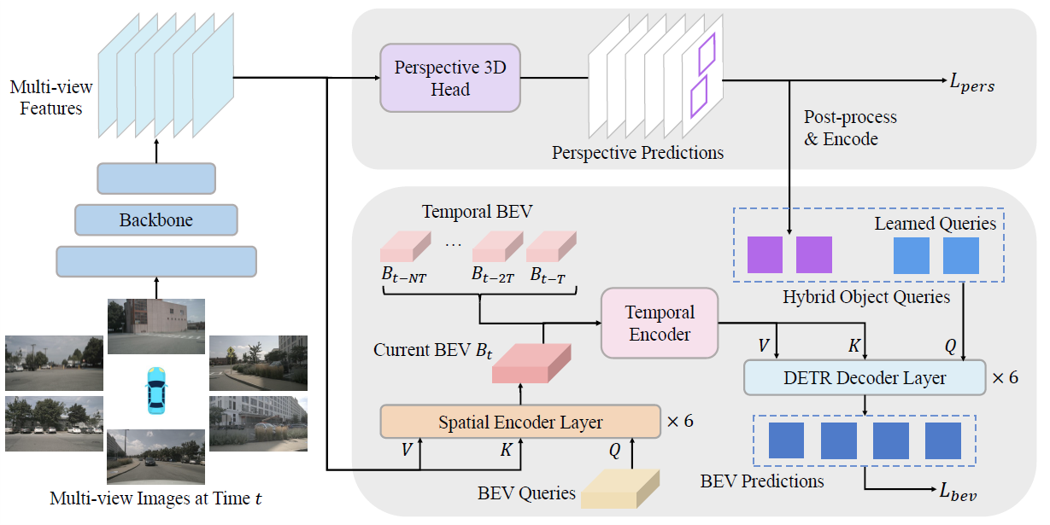
BEVFormer v2: Adapting Modern Image Backbones to Bird's-Eye-View Recognition via Perspective Supervision
CVPR 2023 (Highlight)
·
18 Jun 2023
·
arxiv:2211.10439
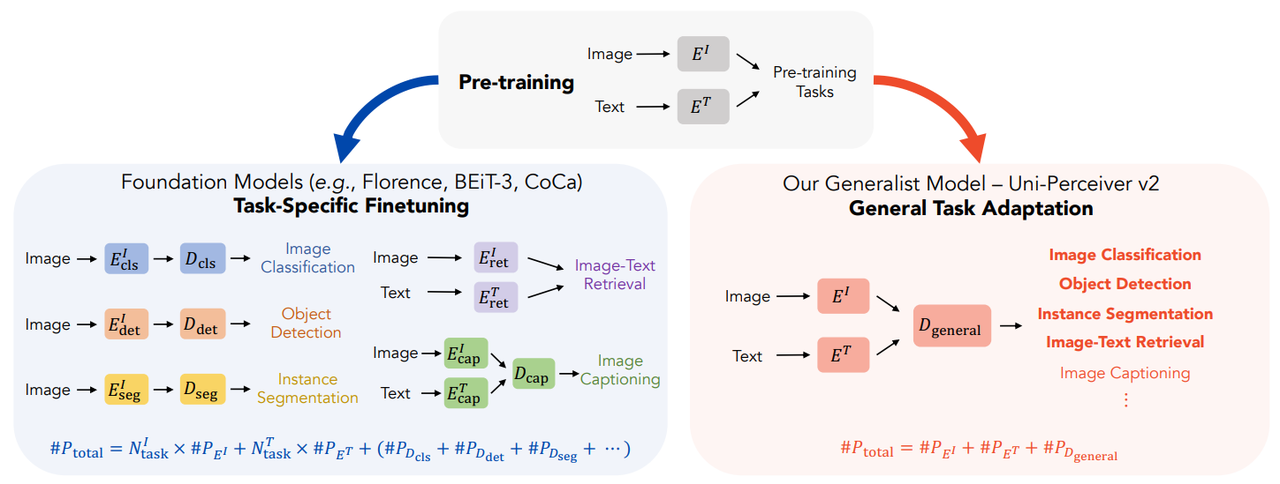
Uni-Perceiver v2: A Generalist Model for Large-Scale Vision and Vision-Language Tasks
CVPR 2023 (Highlight)
·
18 Jun 2023
·
arxiv:2211.09808
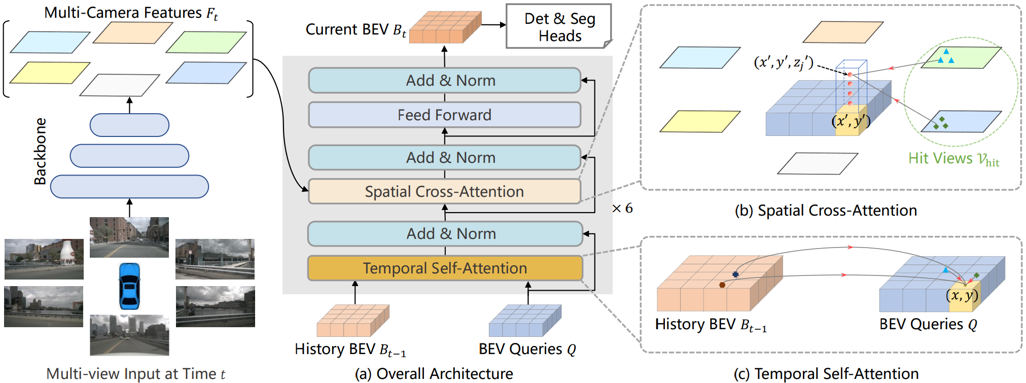
BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
ECCV 2022
·
14 Jul 2022
·
arxiv:2203.17270

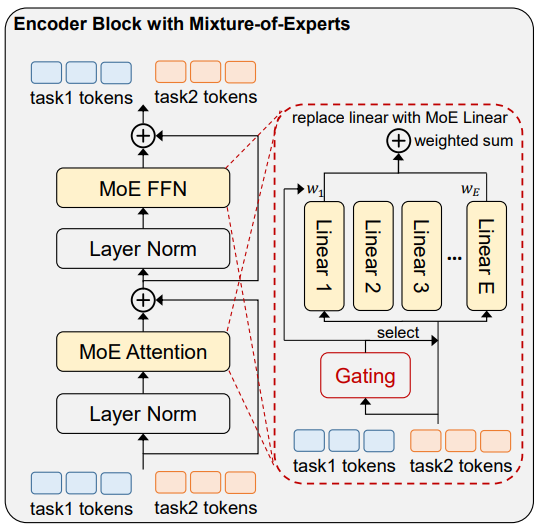
Uni-Perceiver-MoE: Learning Sparse Generalist Models with Conditional MoEs

NeurIPS 2022 (Spotlight)
·
06 Jul 2022
·
arxiv:2206.04674
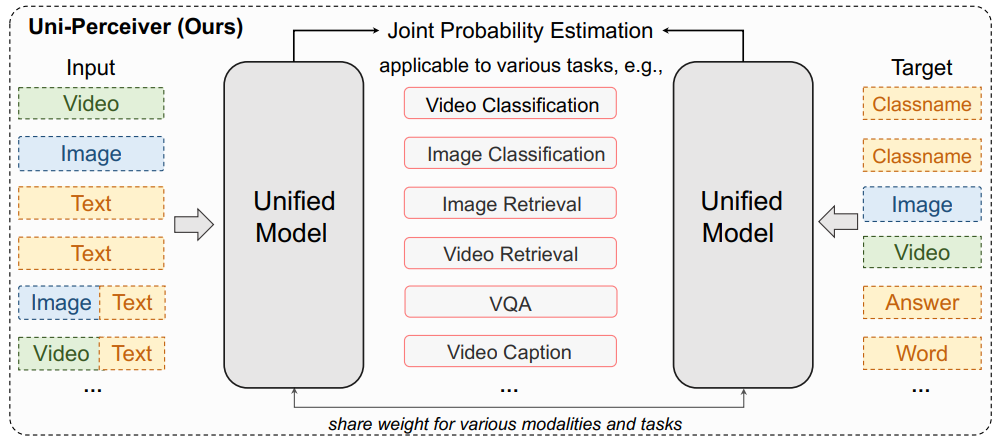
Uni-Perceiver: Pre-training Unified Architecture for Generic Perception for Zero-shot and Few-shot Tasks
CVPR 2022
·
19 Jun 2022
·
arxiv:2112.01522
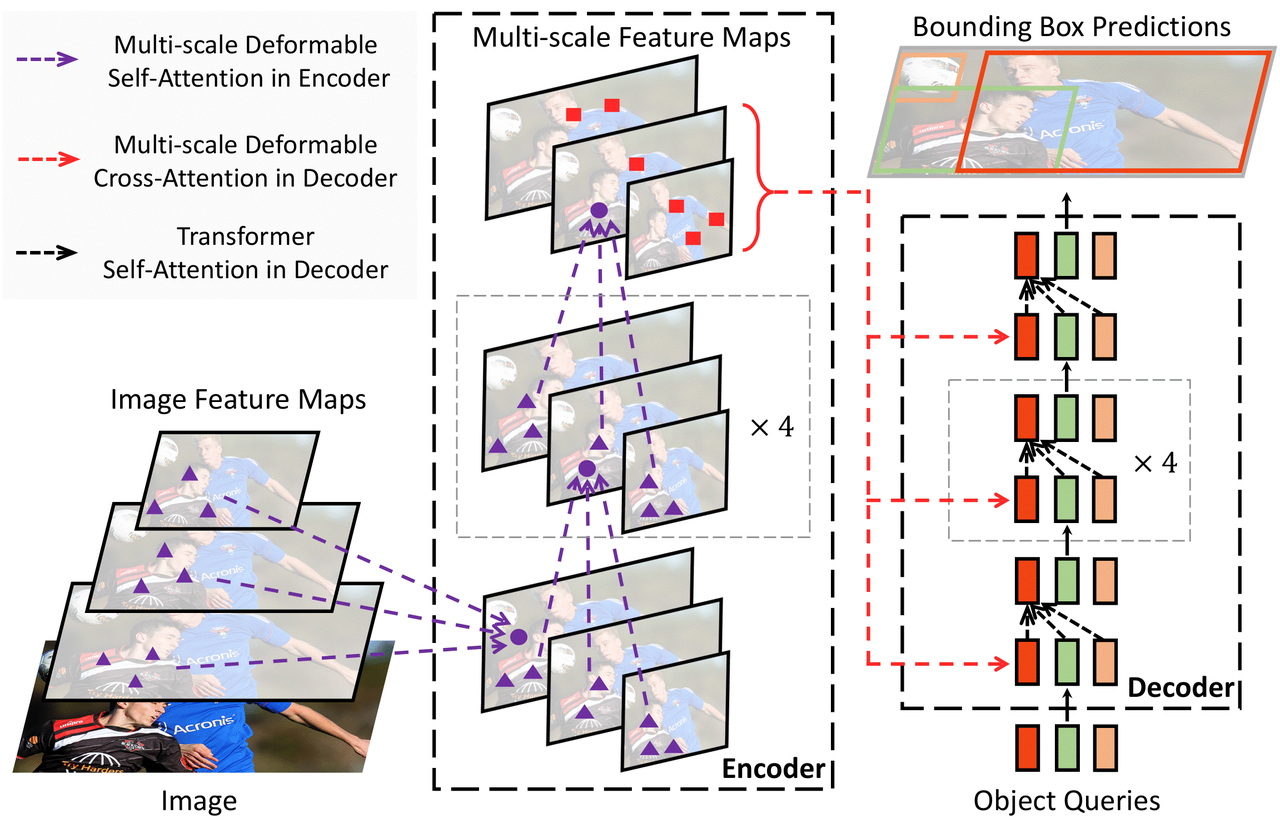
Deformable DETR: Deformable Transformers for End-to-End Object Detection
ICLR 2021 (Oral)
·
04 May 2021
·
arxiv:2010.04159

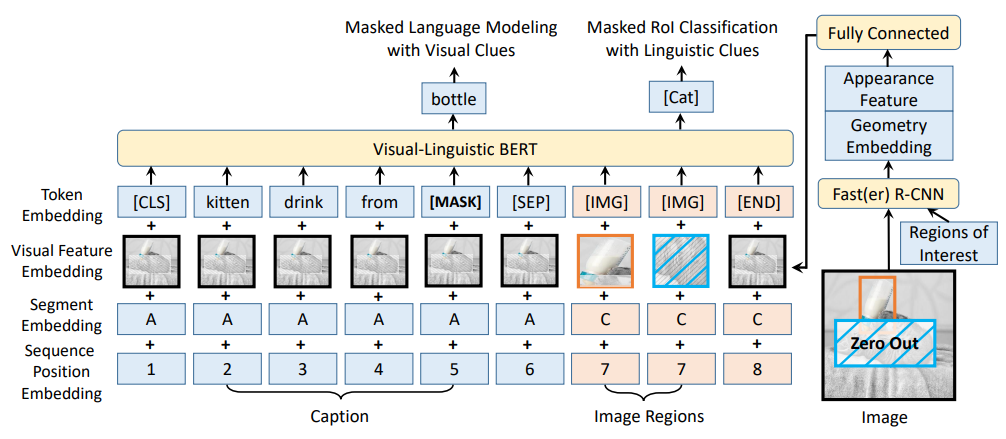
VL-BERT: Pre-training of Generic Visual-Linguistic Representations
ICLR 2020
·
19 Feb 2020
·
arxiv:1908.08530



Flow-Guided Feature Aggregation for Video Object Detection

ICCV 2017
·
21 Aug 2017
·
arxiv:1703.10025

Fully Convolutional Instance-aware Semantic Segmentation

CVPR 2017 (Spotlight)
·
11 Apr 2017
·
arxiv:1611.07709
Convolutional Feature Masking for Joint Object and Stuff Segmentation
CVPR 2015
·
08 Jun 2015
·
arxiv:1412.1283
R-FCN: Object Detection via Region-based Fully Convolutional Networks
NeurIPS 2016
·
05 Dec 2016
·
arxiv:1605.06409


ScribbleSup: Scribble-Supervised Convolutional Networks for Semantic Segmentation
CVPR 2016 (Oral)
·
19 Apr 2016
·
arxiv:1604.05144
Instance-aware Semantic Segmentation via Multi-task Network Cascades

CVPR 2016 (Oral)
·
26 Jun 2016
·
arxiv:1512.04412
BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation
ICCV 2015
·
19 May 2015
·
arxiv:1503.01640
All
2024
The All-Seeing Project V2: Towards General Relation Comprehension of the Open World
Arxiv Tech Report 2024
·
26 Aug 2024
·
arxiv:2402.19474
The All-Seeing Project: Towards Panoptic Visual Recognition and Understanding of the Open World
ICLR 2024
·
07 May 2024
·
arxiv:2308.01907
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Arxiv Tech Report 2024
·
01 May 2024
·
arxiv:2404.16821
MM-Interleaved: Interleaved Image-Text Generative Modeling via Multi-modal Feature Synchronizer
Arxiv Tech Report 2024
·
03 Apr 2024
·
arxiv:2401.10208
Auto MC-Reward: Automated Dense Reward Design with Large Language Models for Minecraft
Arxiv Tech Report 2023
·
02 Apr 2024
·
arxiv:2312.09238
Vision-RWKV: Efficient and Scalable Visual Perception with RWKV-Like Architectures
Arxiv Tech Report 2024
·
08 Mar 2024
·
arxiv:2403.02308
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
CVPR 2024 (Oral)
·
18 Jan 2024
·
arxiv:2312.14238
Efficient Deformable ConvNets: Rethinking Dynamic and Sparse Operator for Vision Applications
CVPR 2024 (Highlight)
·
15 Jan 2024
·
arxiv:2401.06197
2023
DriveMLM: Aligning Multi-Modal Large Language Models with Behavioral Planning States for Autonomous Driving
Arxiv Tech Report 2023
·
27 Dec 2023
·
arxiv:2312.09245
ControlLLM: Augment Language Models with Tools by Searching on Graphs
Arxiv Tech Report 2023
·
19 Dec 2023
·
arxiv:2310.17796
Demystify Transformers & Convolutions in Modern Image Deep Networks
Arxiv Tech Report 2023
·
04 Dec 2023
·
arxiv:2211.05781
Siamese Image Modeling for Self-Supervised Vision Representation Learning
CVPR 2023 (Highlight)
·
18 Jun 2023
·
arxiv:2206.01204
Towards All-in-one Pre-training via Maximizing Multi-modal Mutual Information
CVPR 2023 (Highlight)
·
18 Jun 2023
·
arxiv:2211.09807
BEVFormer v2: Adapting Modern Image Backbones to Bird's-Eye-View Recognition via Perspective Supervision
CVPR 2023 (Highlight)
·
18 Jun 2023
·
arxiv:2211.10439
Uni-Perceiver v2: A Generalist Model for Large-Scale Vision and Vision-Language Tasks
CVPR 2023 (Highlight)
·
18 Jun 2023
·
arxiv:2211.09808
Ghost in the Minecraft: Generally Capable Agents for Open-World Environments via Large Language Models with Text-based Knowledge and Memory
Arxiv Tech Report 2023
·
02 Jun 2023
·
arxiv:2305.17144
VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks
NeurIPS 2023
·
26 May 2023
·
arxiv:2305.11175
InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
CVPR 2023 (Highlight)
·
18 Apr 2023
·
arxiv:2211.05778
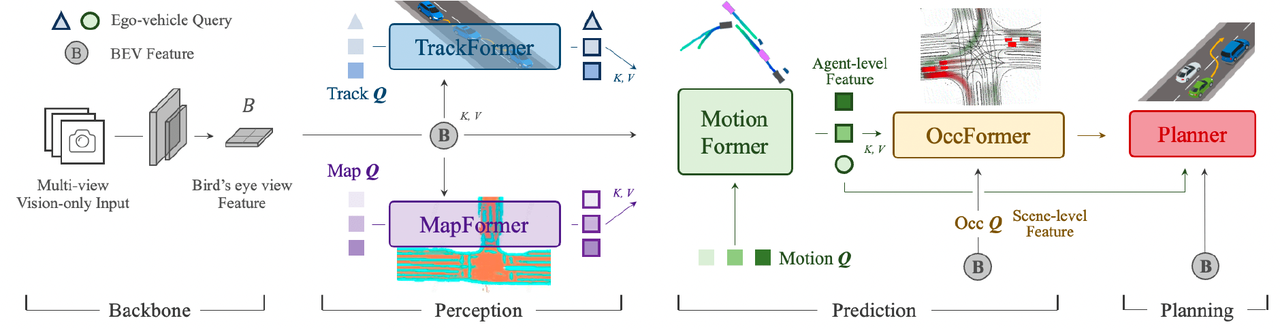
Planning-oriented Autonomous Driving
CVPR 2023 (Best Paper Award)
·
24 Mar 2023
·
arxiv:2212.10156
2022
VL-LTR: Learning Class-wise Visual-Linguistic Representation for Long-Tailed Visual Recognition
ECCV 2022
·
20 Jul 2022
·
arxiv:2111.13579
BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
ECCV 2022
·
14 Jul 2022
·
arxiv:2203.17270
Exploring the Equivalence of Siamese Self-Supervised Learning via A Unified Gradient Framework
CVPR 2022
·
06 Jul 2022
·
arxiv:2112.05141
Uni-Perceiver-MoE: Learning Sparse Generalist Models with Conditional MoEs
NeurIPS 2022 (Spotlight)
·
06 Jul 2022
·
arxiv:2206.04674
AutoLoss-Zero: Searching Loss Functions from Scratch for Generic Tasks
CVPR 2022
·
19 Jun 2022
·
arxiv:2103.14026
Uni-Perceiver: Pre-training Unified Architecture for Generic Perception for Zero-shot and Few-shot Tasks
CVPR 2022
·
19 Jun 2022
·
arxiv:2112.01522
2021
Searching Parameterized AP Loss for Object Detection
NeurIPS 2021
·
09 Nov 2021
·
https://openreview.net/forum?id=hLTZCN7f3M-
Auto Seg-Loss: Searching Metric Surrogates for Semantic Segmentation
ICLR 2021
·
04 May 2021
·
arxiv:2010.07930
Deformable DETR: Deformable Transformers for End-to-End Object Detection
ICLR 2021 (Oral)
·
04 May 2021
·
arxiv:2010.04159
Unsupervised Object Detection with LiDAR Clues
CVPR 2021
·
20 Apr 2021
·
arxiv:2011.12953
2020
VL-BERT: Pre-training of Generic Visual-Linguistic Representations
ICLR 2020
·
19 Feb 2020
·
arxiv:1908.08530
Deformable Kernels: Adapting Effective Receptive Fields for Object Deformation
ICLR 2020
·
13 Feb 2020
·
arxiv:1910.02940
2019
MMDetection: Open MMLab Detection Toolbox and Benchmark
CVPR 2019
·
18 Jun 2019
·
arxiv:1906.07155
Deformable ConvNets v2: More Deformable, Better Results
CVPR 2019
·
16 Jun 2019
·
arxiv:1811.11168
An Empirical Study of Spatial Attention Mechanisms in Deep Networks
ICCV 2019
·
15 Apr 2019
·
arxiv:1904.05873
2018
Integrated Object Detection and Tracking with Tracklet-Conditioned Detection
Arxiv Tech Report 2018
·
28 Nov 2018
·
arxiv:1811.11167
Relation Networks for Object Detection
CVPR 2018 (Oral)
·
15 Jun 2018
·
arxiv:1711.11575
Towards High Performance Video Object Detection for Mobiles
Arxiv Tech Report 2018
·
17 Apr 2018
·
arxiv:1804.05830
Learning Region Features for Object Detection
ECCV 2018
·
20 Mar 2018
·
arxiv:1803.07066
2017
Flow-Guided Feature Aggregation for Video Object Detection
ICCV 2017
·
21 Aug 2017
·
arxiv:1703.10025
Deep Feature Flow for Video Recognition
CVPR 2017
·
06 Jun 2017
·
arxiv:1611.07715
Deformable Convolutional Networks
ICCV 2017 (Oral)
·
06 Jun 2017
·
arxiv:1703.06211
Fully Convolutional Instance-aware Semantic Segmentation
CVPR 2017 (Spotlight)
·
11 Apr 2017
·
arxiv:1611.07709
2016
R-FCN: Object Detection via Region-based Fully Convolutional Networks
NeurIPS 2016
·
05 Dec 2016
·
arxiv:1605.06409
Instance-aware Semantic Segmentation via Multi-task Network Cascades
CVPR 2016 (Oral)
·
26 Jun 2016
·
arxiv:1512.04412
ScribbleSup: Scribble-Supervised Convolutional Networks for Semantic Segmentation
CVPR 2016 (Oral)
·
19 Apr 2016
·
arxiv:1604.05144
Instance-sensitive Fully Convolutional Networks
ECCV 2016
·
30 Mar 2016
·
arxiv:1603.08678
2015
Convolutional Feature Masking for Joint Object and Stuff Segmentation
CVPR 2015
·
08 Jun 2015
·
arxiv:1412.1283
BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation
ICCV 2015
·
19 May 2015
·
arxiv:1503.01640
Generative Modeling of Convolutional Neural Networks
ICLR 2015
·
10 Apr 2015
·
arxiv:1412.6296